
Sudden Surge of Tencent Bots Hits Helsingin Sanomat
Scale and Speed of Automated Article Scraping
Challenges for Media Security and Content Integrity
How Publishers Can Respond and Protect Their Work

Global Digests News delivers timely, credible coverage of world affairs, politics, economy, and technology to keep you informed on today’s top stories.

Bohmian Mechanics: Revisiting Quantum Determinism After New Tests
Bohmian mechanics, once sidelined, returned to focus after a 2025 photon tunneling experiment tested its deterministic claims. The results…

Dark Matter Detection: Innovations Inspired by Henry Cavendish's Experiment
A modern take on Henry Cavendish’s 18th-century torsion balance proposes nested metal shells and ultra-sensitive voltage measurements to de…

Greenland’s Ice Melt Surges Since 1990
Greenland’s ice melt has accelerated sixfold since 1990, driven mainly by rising temperatures rather than atmospheric shifts. Extreme melt…

Health Insurance Marketplaces Leak Sensitive Data to Ad Tech Giants
Nearly all U.S. state health insurance marketplaces have exposed sensitive applicant data—including citizenship and race—to major ad tech f…
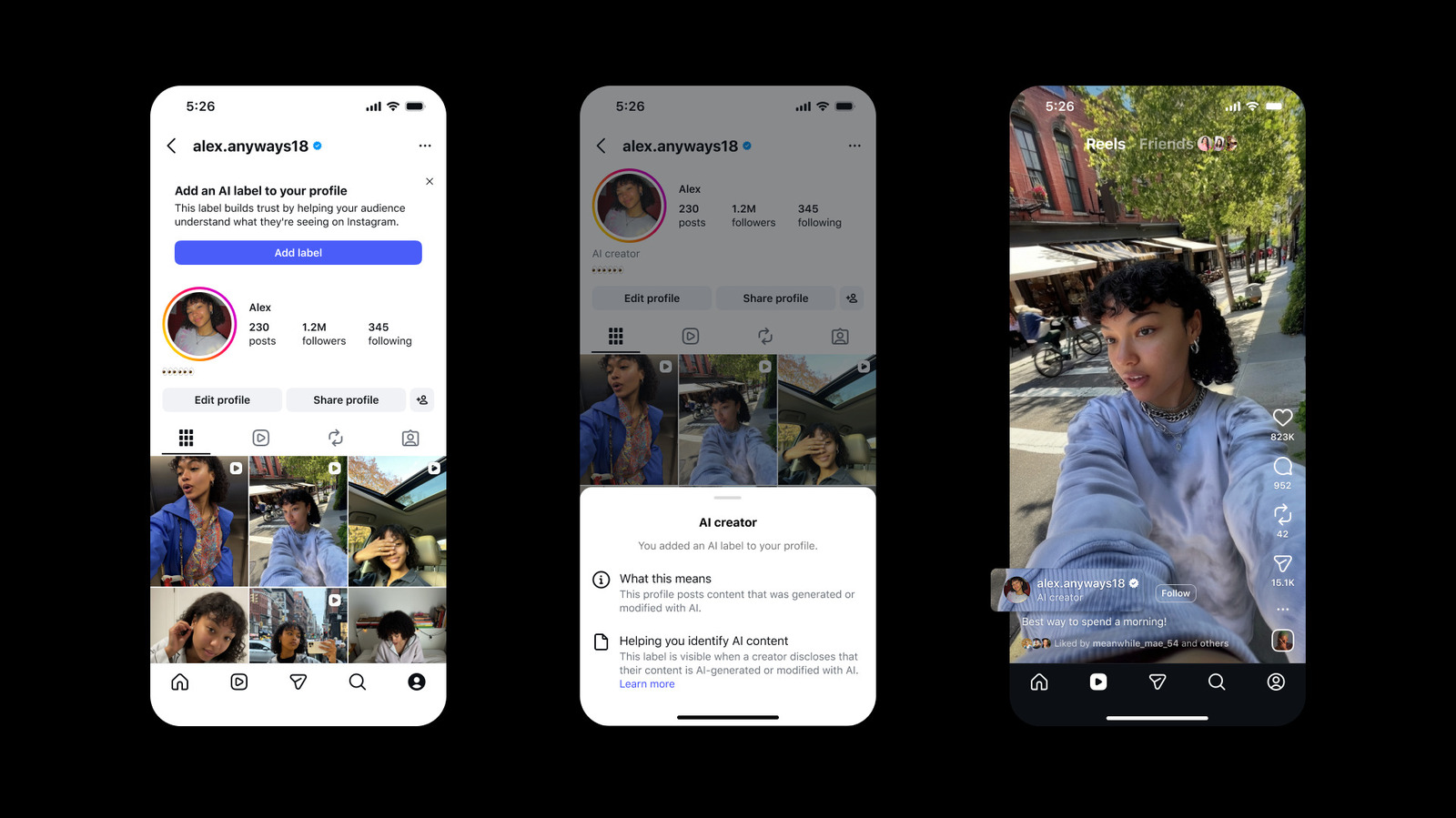
Instagram’s Voluntary AI Creator Label: A Tentative Step Toward Transparency
Instagram has launched an optional “AI creator” label for posts generated or altered by AI. Without automated detection, the system relies…

Uber’s Ambitious Expansion and Innovation
Uber CEO Dara Khosrowshahi lays out a vision to transform Uber into a travel and service platform. By integrating Expedia hotel bookings an…

Claude Code Cost Control: Context Architecture Over Prompt Optimization
Claude Code’s costs stem less from prompt length and more from accumulated context—files, memory, and tool outputs that build up each sessi…

Leonardo da Vinci’s DNA May Finally Be Decoded
Researchers have mapped a 21-generation paternal lineage from 1331 to today, identifying 15 living male descendants of Leonardo da Vinci. G…