
A New Statistical Framework for Auditing Machine Unlearning
How the Relative Three-Sample Test Improves Detection
Challenges in Traditional Machine Unlearning Audits
What This Means for AI Privacy and Compliance
Assessing the Practical Impact of Google’s Approach

Global Digests News delivers timely, credible coverage of world affairs, politics, economy, and technology to keep you informed on today’s top stories.

Elon Musk’s AI Ecosystem Takes Shape
Elon Musk is weaving AI deeply into his ventures—from xAI’s Grok powering X’s conversations to Tesla’s self-driving fleet, Neuralink’s brai…

GitHub Copilot CLI Update Improves Efficiency by Rethinking Task Delegation
GitHub refined Copilot CLI’s task delegation to cut unnecessary handoffs, letting the main agent handle simple tasks directly. This reduces…

Anthropic Blocks AI Access Amid US Security Order
Anthropic has suspended access to its latest AI models, Fable 5 and Mythos 5, following a US government directive targeting foreign users o…

AI Integration in the Workplace: Key Insights from Recent Discussions
Agentic AI is reshaping about 75% of jobs by 2030, demanding new skills like AI literacy and adaptability. Early adopters report productivi…

Stonehenge’s Altar Stone: Glaciers, Not Just Humans, Moved It
New research reveals Stonehenge’s central Altar Stone was likely transported by glaciers from Scotland, challenging the idea that ancient h…

Ocean Origins Debate: External Delivery vs. Internal Production
Recent research challenges the comet impact theory for Earth’s oceans due to isotopic mismatches. Asteroid delivery remains plausible but f…

Security Digest: Oracle PeopleSoft Zero-Day Exploitation
A critical SSRF zero-day in Oracle PeopleSoft exploited by ShinyHunters has compromised nearly 100 organizations, mainly universities, leak…
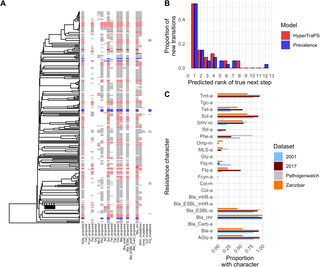
Global Study Maps Divergent Paths of Klebsiella pneumoniae Resistance
A massive analysis of 47,000 Klebsiella pneumoniae genomes from over 100 countries reveals how antimicrobial resistance evolves differently…