
Applying Deep Q-Learning to Connect Four: An Experimental Overview
Recent advances in applying Deep Q-Learning (DQL) to the classic game Connect Four mark a significant step forward in multi-agent reinforcement learning. Unlike traditional tabular methods that struggled with the complexity of multi-player dynamics, this experiment leverages a suite of architectural innovations—such as replay buffers, batched updates, and a highly optimized vectorized environment capable of running 50 to 100 parallel games per second—to achieve measurable progress. After extensive training, the system reduces a random opponent’s win rate from approximately 50% down to 20%, demonstrating genuine learning beyond rote memorization.
However, this progress comes with clear caveats. The design of the opponent pool, while well-suited for multi-agent scenarios, complicates straightforward skill evaluation, and the learning framework has reached a performance plateau. Core challenges persist, notably the instability caused by shifting targets in a non-stationary environment where opponents continuously evolve. These findings underscore that while Deep Q-Learning can break new ground in complex game settings, overcoming inherent engineering hurdles will require specialized, high-efficiency architectures beyond conventional textbook approaches. This experiment thus provides both a milestone and a roadmap for future research in multi-agent reinforcement learning.
Key Architectural Innovations and Training Outcomes
The experiment’s core architectural framework leveraged several critical innovations to address the computational and strategic challenges of applying Deep Q-Learning (DQN) to Connect Four. Central to this was the implementation of a replay buffer, which stored past gameplay experiences to break correlations between sequential moves and stabilize training. Complementing this, batched updates processed multiple training samples simultaneously, improving computational efficiency and enabling faster convergence.
Another key innovation was the use of a vectorized environment capable of running 50 to 100 parallel games per second. This design dramatically increased data throughput, allowing the agent to experience a wide variety of game states within a feasible training timeframe. By scaling gameplay in parallel, the model could better generalize across the complex state space of Connect Four, which poses significant challenges compared to single-agent or turn-based environments.
Training progressed over one million steps, during which the agent’s performance improved markedly. The win rate of a random opponent against the trained DQN agent dropped from roughly 50% to about 20%, a clear indication that the model had learned meaningful strategies beyond random play. However, despite this progress, the agent struggled to achieve robust defensive tactics, highlighting persistent gaps in strategic depth.
The experiment also introduced an opponent pool or “zoo” consisting of various trained agents to simulate a multi-agent environment. While this approach better reflects the dynamics of multi-player games, it complicated the evaluation of absolute skill levels. DQN-versus-DQN matchups tended to yield win rates near 50%, reflecting the inherent balance between similarly trained agents rather than a definitive measure of superiority.
Despite these architectural advances and performance gains, the study acknowledged a clear performance ceiling. The principal bottleneck identified was the instability arising from non-stationary targets, a consequence of training against an evolving opponent. This shifting landscape undermines convergence and remains a core engineering challenge. The findings suggest that conventional DQN architectures, even with optimized replay and batching techniques, are insufficient for mastering multi-agent Connect Four without further innovation.
In summary, the experiment’s architectural choices enabled significant forward strides in applying Deep Q-Learning to a complex multi-agent board game. Yet, the results also underscore the need for specialized, high-efficiency architectures and novel stabilization methods to overcome the fundamental instability and performance plateaus currently limiting progress.
Challenges of Multi-Agent Reinforcement Learning in Board Games
Multi-agent reinforcement learning (MARL) in board games like Connect Four presents unique challenges that distinguish it from single-agent scenarios. Unlike environments with fixed dynamics or stationary opponents, MARL involves agents learning simultaneously while adapting to each other’s evolving strategies. This non-stationarity creates shifting target distributions that destabilize learning algorithms such as Deep Q-Learning, which rely on relatively stable reward structures to converge effectively.
Additionally, the inherent complexity of multi-player interactions demands architectural innovations to handle diverse opponent behaviors and maintain sample efficiency. Traditional tabular reinforcement learning methods falter in this context due to their inability to scale and generalize across the combinatorial explosion of game states and action sequences. The need for high-throughput training environments—capable of running many parallel games—and mechanisms like replay buffers and batched updates is therefore paramount to gather sufficient experience and stabilize policy updates.
Despite these advances, fundamental engineering challenges persist. Chief among them is the instability caused by constantly shifting opponent policies, which disrupts the learning target and hinders convergence. This instability limits the achievable performance ceiling, as demonstrated by the plateau in win-rate improvements after extensive training. Addressing these issues will require specialized architectures and algorithms designed explicitly for multi-agent settings, moving beyond textbook Deep Q-Learning frameworks to incorporate mechanisms for opponent modeling, non-stationarity mitigation, and efficient exploration in dynamic competitive environments.
Understanding the Limits of Current Deep Q-Learning Approaches
The recent experiment applying Deep Q-Learning to Connect Four marks a meaningful advance over traditional tabular reinforcement learning approaches, demonstrating that neural-network-based agents can achieve measurable skill improvements in a multi-agent environment. For practitioners and researchers, this progress confirms that computationally intensive architectural strategies—such as replay buffers, batched updates, and massively parallelized simulations—are essential to scale learning in competitive board games beyond simplistic baselines.
However, the findings also underscore significant practical limitations that temper immediate expectations for Deep Q-Learning’s efficacy in multi-agent settings. The persistent instability caused by constantly shifting opponent strategies presents a fundamental barrier, preventing the agent from reliably mastering defensive tactics or surpassing a certain performance plateau. This instability reflects a broader challenge in reinforcement learning: non-stationary environments require more sophisticated mechanisms to stabilize training and ensure consistent policy improvement.
For industry stakeholders and AI developers, these results imply that deploying Deep Q-Learning-based agents in real-world multi-agent scenarios—such as automated negotiation, strategic gaming, or adaptive control systems—will demand innovations beyond standard textbook algorithms. The ceiling observed here signals a need for specialized architectures that can handle dynamic opponent modeling and maintain stable learning targets over time.
From a policy perspective, understanding these limitations is crucial when evaluating claims about AI capabilities in competitive or adversarial domains. While Deep Q-Learning exhibits promise, its current constraints highlight the importance of cautious optimism and continued investment in foundational research to address core engineering challenges.
Ultimately, this experiment serves as a valuable benchmark, clarifying where Deep Q-Learning stands today and charting a clear direction toward future research priorities. Advancements that incorporate opponent-aware strategies, meta-learning, or hybrid reinforcement models may be necessary to break through the present performance ceiling and unlock the full potential of AI in complex multi-agent environments.
Future Directions for Advancing AI in Multi-Player Games
Looking ahead, the trajectory of AI research in multi-player games like Connect Four hinges on addressing the persistent instability inherent in multi-agent reinforcement learning frameworks. The current Deep Q-Learning approach demonstrates meaningful progress, yet the plateau in performance underscores that conventional architectures and training paradigms are insufficient for mastering complex interactive environments. Readers should watch for advances in algorithms explicitly designed to stabilize learning when opponents are simultaneously adapting—such as opponent modeling techniques, meta-learning strategies, or novel experience replay schemes that better handle non-stationarity.
Another key milestone will be the development of more efficient, scalable architectures capable of running extensive parallel simulations without sacrificing training stability. Innovations in vectorized environments, prioritized replay buffers tailored for multi-agent dynamics, and asynchronous update mechanisms could collectively push beyond the current computational bottlenecks. Furthermore, benchmarks incorporating diverse opponent pools with transparent skill metrics will be crucial to objectively quantify improvements and disentangle relative gains from stochastic win-rate clustering.
Finally, the broader AI research community’s exploration of multi-agent reinforcement learning in increasingly realistic and strategic settings will provide valuable insights transferable to Connect Four and similar games. Progress in these areas—grounded in rigorous experimentation and transparent reporting—will illuminate pathways toward overcoming the core challenges highlighted in this study. For practitioners and enthusiasts tracking these developments, the next signals to monitor include published results on stability-enhancing algorithmic modifications, open-source implementations of multi-agent environments with rigorous evaluation protocols, and empirical evidence demonstrating consistent skill advancement beyond current ceilings.
Frequently Asked Questions about Deep Q-Learning on Connect Four
Deep Q-Learning (DQL) extends traditional tabular reinforcement learning by using neural networks to approximate the Q-value function instead of relying on explicit tables. This allows DQL to handle much larger and more complex state spaces, such as those encountered in Connect Four, where enumerating all possible states is infeasible. Unlike tabular methods, DQL leverages experience replay and batched updates to stabilize training and improve sample efficiency.
Why is Connect Four a challenging game for multi-agent reinforcement learning?
Connect Four poses a unique challenge for multi-agent reinforcement learning because it is a competitive, turn-based game with a large state space and non-stationary dynamics. Each agent’s policy evolves during training, causing shifting targets that destabilize learning. Additionally, the presence of multiple opponents requires strategies that can adapt to diverse play styles, complicating the learning process beyond single-agent environments.
What architectural choices were critical to achieving progress in this Deep Q-Learning experiment?
Key architectural innovations included the use of replay buffers to break correlations between sequential experiences, batched network updates for computational efficiency, and a vectorized environment capable of running 50 to 100 parallel Connect Four games per second. These elements were essential to scaling training and enabling the network to learn meaningful policies that significantly reduced the random opponent’s win rate.
What are the main limitations encountered in applying Deep Q-Learning to Connect Four?
The primary limitations stem from instability caused by non-stationary opponents, which leads to shifting learning targets and caps performance improvements. Despite reducing the random opponent’s win rate substantially, the trained agent still struggles with basic defensive strategies. Moreover, the design of the opponent pool complicates direct measurement of skill level, as DQN agents tend to produce win rates near 50% against each other regardless of absolute ability.

Global Digests News delivers timely, credible coverage of world affairs, politics, economy, and technology to keep you informed on today’s top stories.

Bohmian Mechanics: Revisiting Quantum Determinism After New Tests
Bohmian mechanics, once sidelined, returned to focus after a 2025 photon tunneling experiment tested its deterministic claims. The results…

Dark Matter Detection: Innovations Inspired by Henry Cavendish's Experiment
A modern take on Henry Cavendish’s 18th-century torsion balance proposes nested metal shells and ultra-sensitive voltage measurements to de…

Greenland’s Ice Melt Surges Since 1990
Greenland’s ice melt has accelerated sixfold since 1990, driven mainly by rising temperatures rather than atmospheric shifts. Extreme melt…

Health Insurance Marketplaces Leak Sensitive Data to Ad Tech Giants
Nearly all U.S. state health insurance marketplaces have exposed sensitive applicant data—including citizenship and race—to major ad tech f…
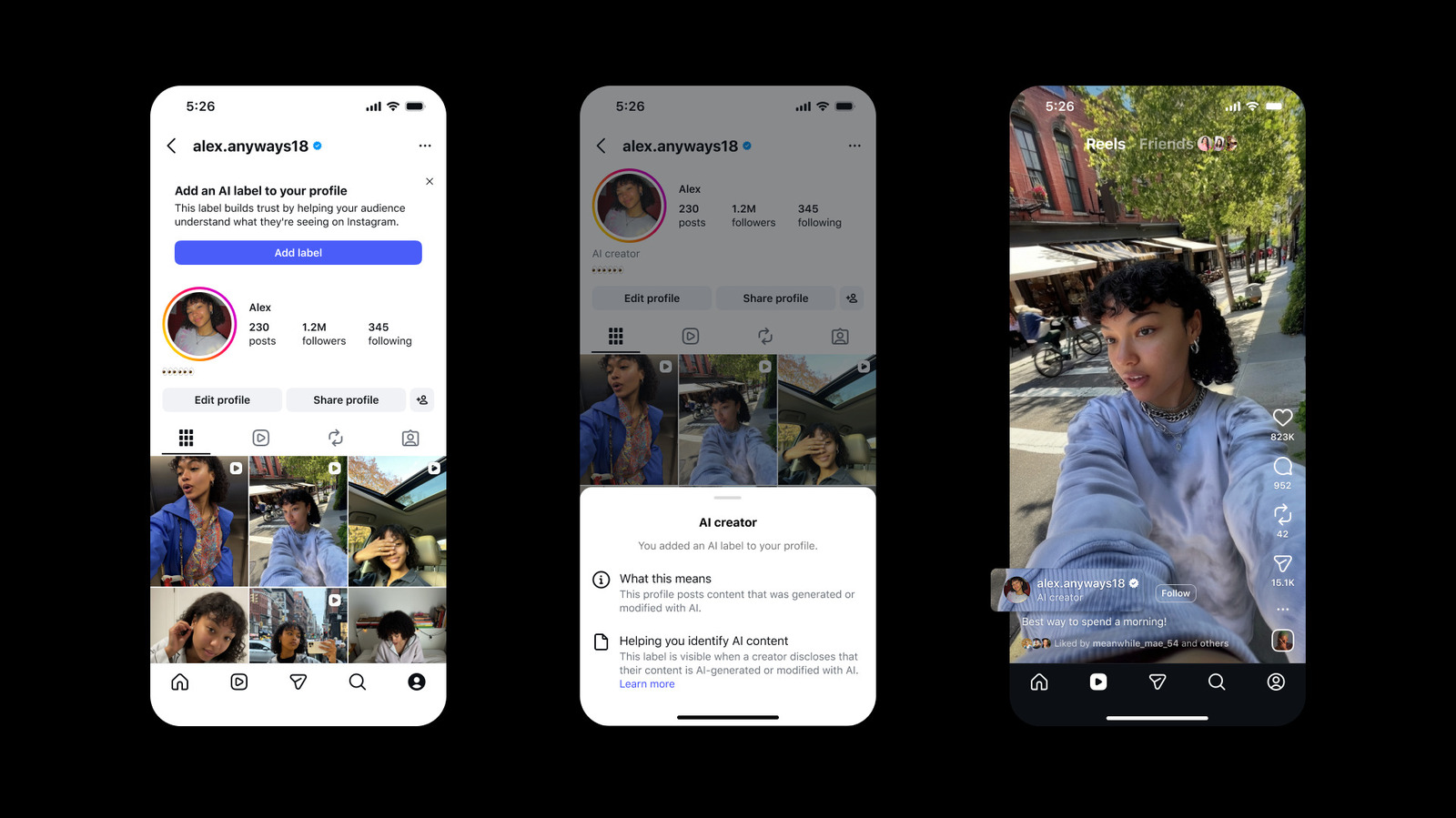
Instagram’s Voluntary AI Creator Label: A Tentative Step Toward Transparency
Instagram has launched an optional “AI creator” label for posts generated or altered by AI. Without automated detection, the system relies…

Uber’s Ambitious Expansion and Innovation
Uber CEO Dara Khosrowshahi lays out a vision to transform Uber into a travel and service platform. By integrating Expedia hotel bookings an…

Claude Code Cost Control: Context Architecture Over Prompt Optimization
Claude Code’s costs stem less from prompt length and more from accumulated context—files, memory, and tool outputs that build up each sessi…

Leonardo da Vinci’s DNA May Finally Be Decoded
Researchers have mapped a 21-generation paternal lineage from 1331 to today, identifying 15 living male descendants of Leonardo da Vinci. G…