Bright Data SDK Embedded in Consumer Devices
Smart TVs as Persistent Proxy Nodes
How User Consent Masks Data Collection
Privacy Risks and Security Concerns
Transparency Must Improve for Device Users

Global Digests News delivers timely, credible coverage of world affairs, politics, economy, and technology to keep you informed on today’s top stories.
Digest: BitBoard AI-Powered Dashboard and Reporting Tool
BitBoard combines AI chat and coding agents to build dashboards that connect live data and manual inputs. It stores queries and scripts for…

Cloudflare’s Acquisition of VoidZero: Navigating Risks in JavaScript Tooling
Cloudflare’s acquisition of VoidZero brings popular open-source tools like Vite under corporate control, raising questions about ecosystem…

Media Duplication and DRM Evolution: Insights from Patrick Quirk
Copying digital media has shifted from a costly, legally fraught process in 1999 to a routine task today. Legacy DRM and hardware restricti…

Digest: Headless Systems and AI Interaction Evolution
Headless systems ditch traditional user interfaces, letting AI agents interact directly with software through APIs and protocols like MCP.…
Tech Digest: Nvidia’s New CPU System
Nvidia is developing a high-performance CPU system aimed at Windows PCs, blending GPU expertise with CPU design to tackle complex workloads…
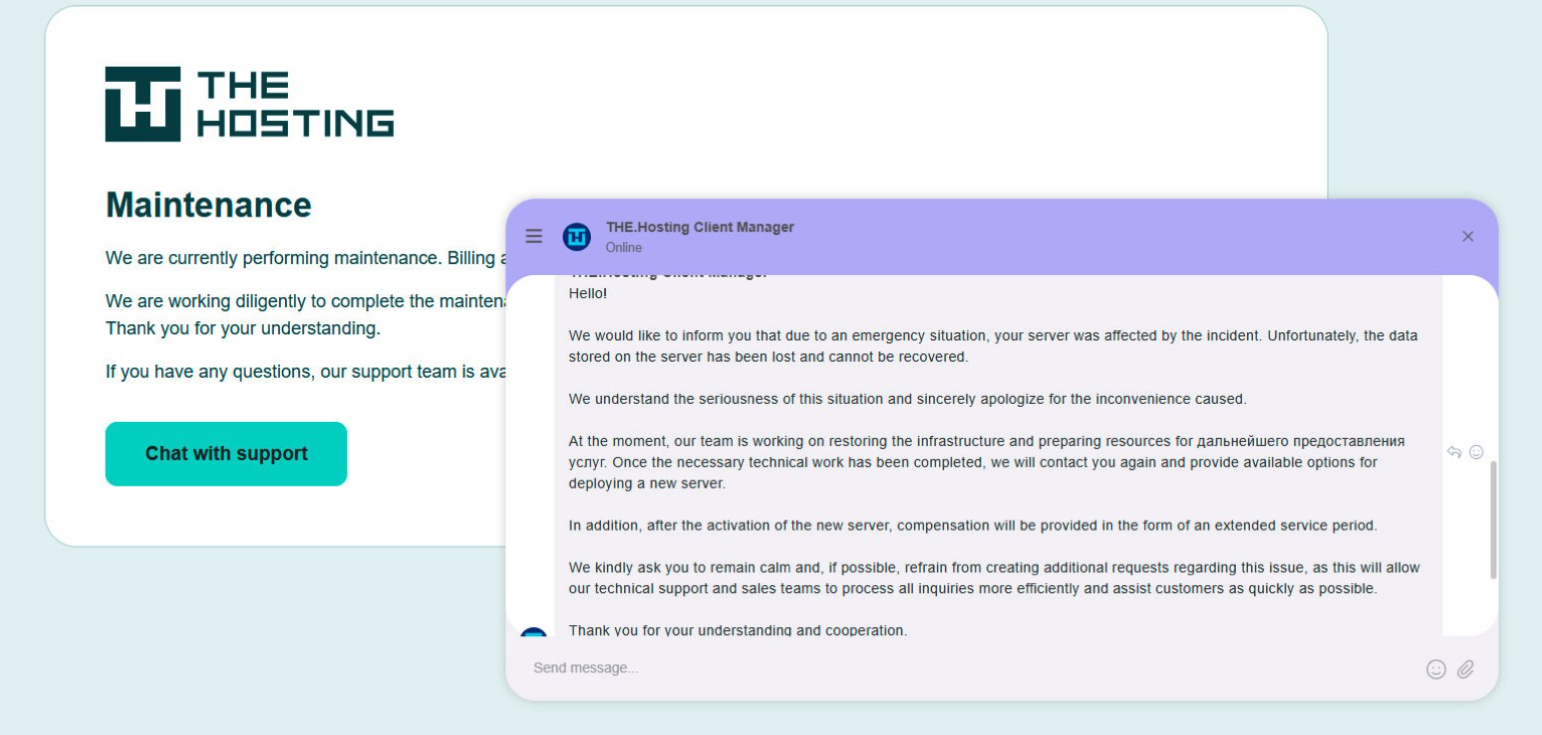
Dutch Authorities Disrupt Cybercrime Network Backing Russian Hybrid Warfare
Dutch law enforcement arrested two men linked to hosting firms supporting Russian cyberattacks inside the EU. Over 800 servers tied to Star…

Cloudflare’s AI Spend Controls Bring Clarity to Cost Chaos
Cloudflare’s new AI Gateway spend controls let companies unify billing and set real-time, granular limits by user, team, model, or provider…

Security Risks Ahead of FIFA World Cup 2026
As FIFA World Cup 2026 approaches, cybercriminals are ramping up scams targeting fans through fake websites, phishing, malicious apps, and…