
Cloudflare's Billing Pipeline Hits Unexpected Slowdown
Tracing Reveals Lock Contention and Mutex Waits
How Partitioning Changes Affected Query Performance
Optimizations That Cut Latency and Boost Stability
Lessons for Database Tuning at Scale

Global Digests News delivers timely, credible coverage of world affairs, politics, economy, and technology to keep you informed on today’s top stories.

When Defenders Turn Weapon: The Botnet Attacks Tied to a Brazilian DDoS Firm
A Brazilian DDoS protection company, Huge Networks, was linked to a botnet launching massive attacks on local ISPs. The CEO blames a breach…
OWASP’s Bold Vision to Eliminate Insecure Software
The OWASP Foundation’s 2026 strategic plan aims to eradicate insecure software by mobilizing a global community around education, open inno…
Scorched Earth 2000 Reloaded for Browsers
Scorched Earth 2000, the classic DOS artillery game, has been ported to run directly in modern browsers using HTML and JavaScript. AI tools…

Cloudflare Cuts 1,100+ Jobs, Blames Agentic AI Shift
Cloudflare is cutting over 1,100 jobs worldwide, citing a 600% surge in internal AI use as the driver behind a structural realignment aimed…
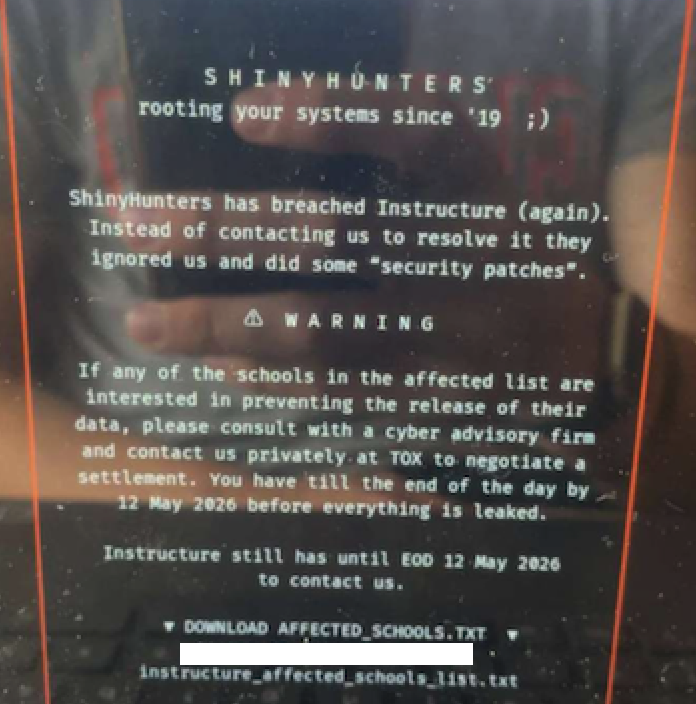
Canvas Cybersecurity Breach Shakes U.S. Education System
The ShinyHunters group exposed sensitive data of 275 million students and faculty across nearly 9,000 U.S. schools. Instructure’s repeated…
Numa v0.14 Launches Self-Hosted ODoH Relay
Numa v0.14 debuts a self-hosted Oblivious DNS over HTTPS relay bundled in a single Rust binary, offering a privacy-preserving DNS architect…

SEO and Generative AI: Key Insights from Google's New Resource
Google’s fresh guide on AI-optimized SEO cuts through hype to stress that originality and user value still drive search rankings. It debunk…

Microsoft Exchange Server Under Active Attack: CVE-2026-42897 Exploitation Demands Immediate Action
A critical cross-site scripting flaw in Microsoft Exchange Server 2016, 2019, and Subscription Edition is actively exploited via malicious…